Making PDFs Searchable
I make use of the advanced search feature in Zotereo frequently, which enables searching through manuscript PDFs. However, when you obtain manuscript PDF files from online databases, they may not be in a searchable format. This means you are unable to highlight and search for text within the PDF. I have written a small Python function that will recursively search though a directory and convert any found PDF to a searchable format.
Optical Character Recognition (OCR) is a method to enable text recognition within images and documents. PDFs contain vector graphics that can contain raster objects (.png, .jpg etc.). The OCR process will first rasterize each page of the PDF file then an OCR “layer” is created.
Getting Started
The code to perform the bulk OCR conversion can be found in this GitHub repository. Once you have the project repository stored locally, follow these steps to run OCR on your Zotereo database.
You will need to install the command-line program OCRmyPDF.
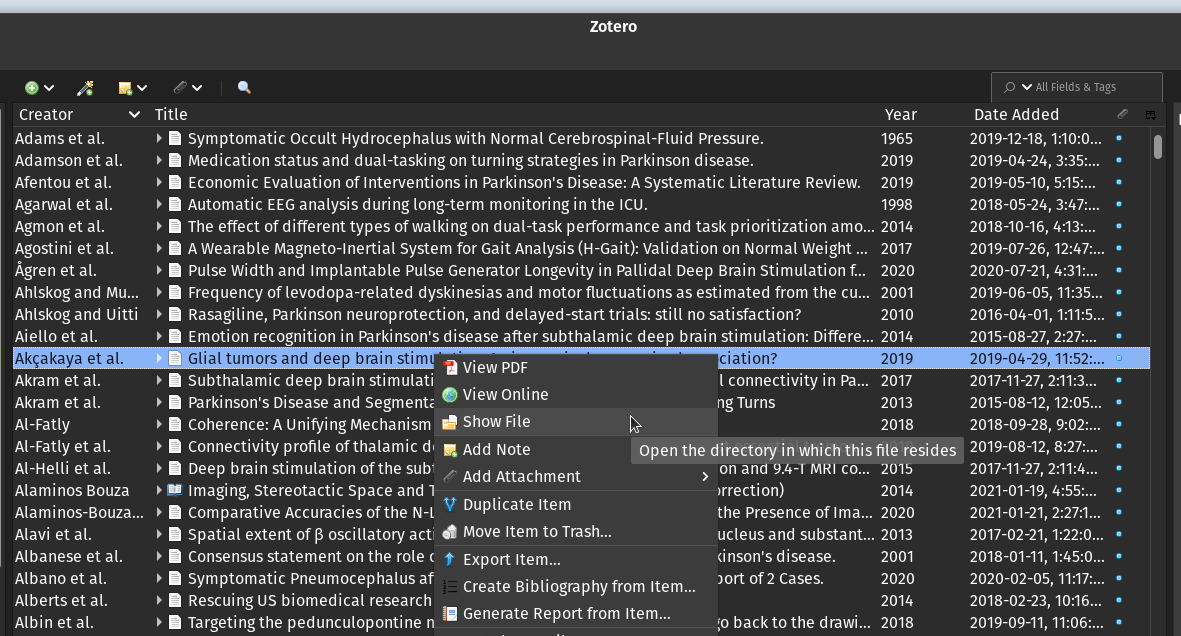
Next, you will need to determine where Zotereo stores your PDF files. In Zotereo, right-click on any document and select Show File. A new window will pop-up, make note of the full path to parent directory (i.e. /home/Zotereo/storage).
In a terminal window, change into the GitHub project repository:
cd /home/user/Documents/Github/ocr-pdfInstall the required Python libraries by running:
python -m pip install -r requirements.txtFrom the root of the repository, run the Python script by passing the full directory path determined in the first step:
python main.py -i "full/path/to/PDF/storage/directory"
This process will take some time. First, the algorithm will search through all the PDFs and determine which files are not searchable. Once the non-searchable PDF files have been found, the OCR process is executed using ocrmypdf.